intrinsic 指令
由于浮点指令使用特殊寄存器(即浮点寄存器),所以在使用浮点指令时,操作数会加载到浮点寄存器中,操作完成之后再从寄存器拷贝出来。而且一些指令支持向量并行操作,所以手动汇编相对比较困难,而如果需要指定使用,则可以使用编译器提供的内联函数。这里主要记录 x86 的浮点内联函数,arm 也有浮点内联函数。
intel ICC 编译器和 gcc 编译支持 MME/SSE/AVX 的 C 接口,且两者命名基本相同( gcc 主要通过头文件对一些 __builtin_xxxx 的封装),关于支持了一些浮点内联函数,头文件,操作细节,版本,可见 intel 官网查询
下面是这类函数大概的格式
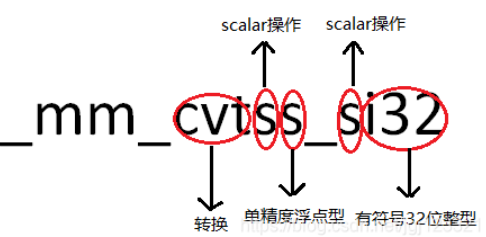
- 指令版本:
_mm开头为sse指令,_mm256为AVX指令 - 指令:
cvtss为操作指令,这里是转化 ss 为标量单精度,实际有这样的汇编指令(ps为向量单精度,ss为标量单精度,pd为向量双精度,sd为标量双精度,等) - 数据类型:
si32为标量32位有符号整形
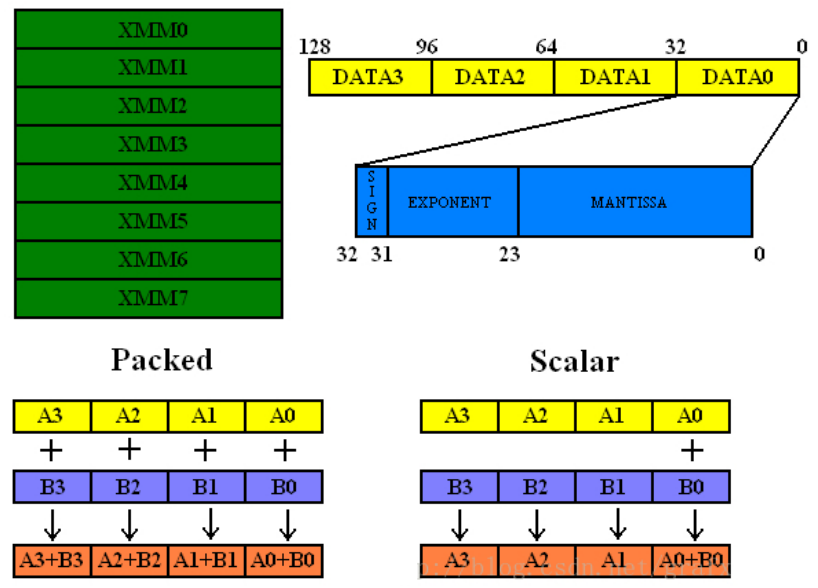
寄存器分为标量与矢量
- 标量:就是一个一个,单个定义的数据
- 矢量:又称向量,或者打包的标量,是一组标量
寄存器类型命名
| 命名 | 含义 |
|---|---|
| __m128 | 包含 4 个 float 向量 |
| __m128d | 包含 2 个 double 向量 |
| __m128i | 包含若干个整形数字向量 |
| __m256 | 包含 8 个 float 向量 |
| __m256d | 包含 4 个 double 向量 |
| __m256i | 包含若干个整形数字向量 |
数据类型定义
| 类型 | 含义 |
|---|---|
| s | Scalar 变量指令 |
| p | Packed 包裹指令 |
| s | 32 位 float |
| d | 64 位 double |
| i32 | 带符号 32 位整形 |
| i64 | 带符号 64 位整形 |
| u32 | 无符号 32 位整形 |
| pixx | xx 为长度,packed 操作所有的 xx 位有符号整形,使用寄存器长度为 64 位 |
| epixx | xx 为长度,packed 操作所有的 xx 位有符号整数,使用寄存器长度为 128 位 |
| epuxx | xx 为长度,packed 操作所有的 xx 位无符号整数 |
| ss | 第一个单精度 |
| sd | 第一个双精度 |
| ps | 向量中所有的单精度 |
| pd | 向量中所有的双精度 |
使用举例
double a = 3.0f;
double b = 4.0f;
double c = 0.0f;
// 首先将 a b 加载到寄存器中
__m128d n = _mm_set_sd(a);
__m128d m = _mm_set_sd(b);
// 执行标量除法(即浮点寄存器第一个双精度数据参与除法运算)
n = _mm_sub_sd(n, m);
// 在从寄存器取出转化到 double 类型内存变量中
c = _mm_cvtsd_f64(n);
再看 intel 对 _mm_sub_sd 函数介绍
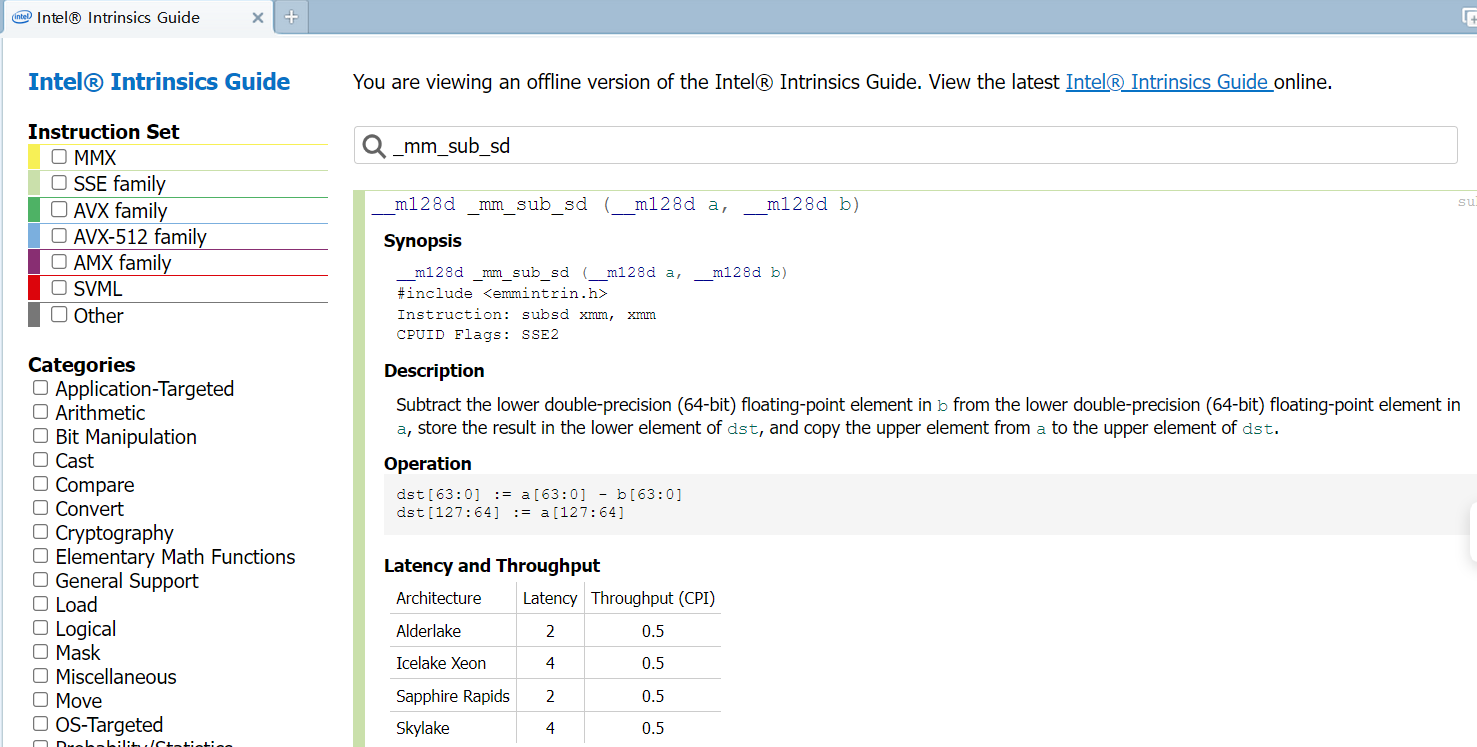
包含了函数原型,头文件,对应指令用法,CPUID 检测标志,描述,操作过程(这对于指令模拟比较重要),以及在各个架构中的性能。下面是一些头文件和对应指令版本,仅参考:
#include <mmintrin.h> // mmx
#include <xmmintrin.h> // sse
#include <emmintrin.h> // sse2
#include <pmmintrin.h> // sse3
#include <tmmintrin.h> // sse3
#include <intrin.h> // 不关心哪个版本
ARM 浮点指令简单介绍
arm 浮点指令除了 VFP 还有 NEON。NEON 支持整数、定点和单精度浮点 SIMD 运算。是针对高级媒体和信号处理应用程序以及嵌入式处理器的 64/128 位混合 SIMD 技术。 它是作为 ARM 内核的一部分实现的,但有自己的执行管道和寄存器组,该寄存器组不同于 ARM 核心寄存器组。
VFP 指令用 FADD,NEON 指令用 VADD。
NEON 指令集比 VFP 指令集更广泛,因此,尽管大多数 VFP 指令具有等效的 NEON 指令,但仍有许多 NEON 指令执行 VFP 指令无法执行的操作。
ARMv5 开始引入了 VFP (Vector Floating Point) 指令,该指令用于向量化加速浮点运算。自 ARMv7 开始正式引入 NEON 指令,NEON 性能远超 VFP,因此 VFP 指令被废弃。类似于 Intel CPU 下的 MMX/SSE/AVX/FMA 指令。
